 Предназначение Предназначение
Предназначение ПредназначениеSDK Pullenti Unitext предназначено для выделения из файлов разных форматов текстовых данных вместе со структурирующими их элементами типа таблиц, списков, сносок и др.
Продукт Non-Commercial Freeware & Commercial Software, то есть бесплатен для некоммерческого использования и небесплатен для коммерческого.
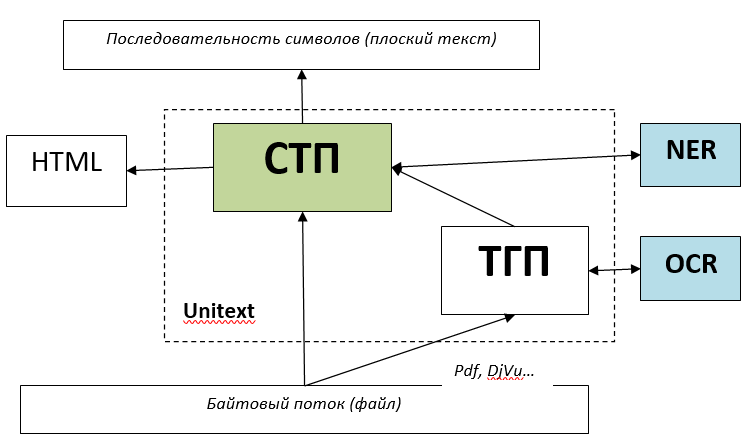
Извлекается не просто плоский текст, а плоский текст вместе с элементами, которые могут этот плоский текст содержать. Также выделяются картинки, если они есть. Совокупность такой информации будем называть структурно-текстовым представлением (СТП). Оно имеет древовидную (иерархическую) структуру: с корнем - самим документом, и вершинами - элементами разных типов. Стили текстов и абзацев также извлекаются для некоторых форматов, но эти данные являются "факультативными".
Поддерживается широкий спектр форматов: Doc, Docx, Pdf, Rtf, Html и другие, полный список см. далее. Отметим, что если в файле тексты отсутствуют в явном виде, то они и не выделятся. Например, если PDF не содержит текстового слоя, а только изображения, то на выходе получим только картинки, так как OCR-распознавания в SDK нет.
Из СТП можно получить плоский текст путём конкатенации его текстовых элементов, с потерей информации об исходном структурировании.
Некоторые форматы (Pdf, DjVu, Mdi, Sgv) имеют специфическое представление, которое будем называть тексто-графическим представлением (ТГП). Оно состоит из последовательности страниц и координатном распределении на страницах фрагментов текста. Это представление также выделяется из исходного файла и связывается со СТП, то есть Unitext содержит оба представления: СТП и ТГП.
SDK представлено функционально эквивалентным кодом на различных языках программирования: C#, Java, Python и Javascript. Исходный код вместе с этой документацией генерируется автоматически из исходного кода C# с помощью специально разработанного конвертера UniSharping. SDK работает на всех операционных системах и платформах, где поддержаны вышеуказанные языки. Свежую версию SDK можно скачать с сайта Pullenti.
Для своей работы SDK не требует никаких дополнительных установок или внешнего ПО, а ограничивается стандартными библиотеками используемого языка программирования.
Использование SDK в JavaДля использования SDK нужно добавить в свой проект всё содержимое пакета com.pullenti.
Файлы в кодировке UTF-8, но BOM убран по многочисленным просьбам, так как с чем-то он конфликтует. В связи с этим в настройках проекта Eclipse нужно явно указать кодировку UTF-8.
Исходные коды Java получены путём автоматического конвертирования из исходников C#. Языки близкие, но есть различия, к которым относятся перечисления (enum) и перегрузки операций. В C# с полями перечислений можно производить арифметические и логические операции, в Java - нет. Поэтому приходится конвертировать enum C# в класс Java, а поля оформлять его статическими экземплярами public static final с числовым полем value, а операции производить над ними. Например, см. перечисление FileFormat. Те из системных классов, полных аналогов которых не нашлось в Java, получили свои реализации в пакете com.pullenti.unisharp. В остальном всё практически идентично. Код получился функционально эквивалентным, что проверено на многочисленных Unit-тестах, также переведённых в Java и отработавших правильно. Ниже примеры даются на C#, позже переделаем их на Java.
Быстрый стартОсновным является класс UnitextDocument, содержащий результат обработки файла, то есть структурно-текстовое и, возможно, тексто-графическое представления. Создаётся статической функцией createDocument.
UnitextDocument doc = UnitextService.createDocument("test.rft", null);
Вторым параметром можно передать массив с содержимым файла, если он имеется в памяти (например, при серверной обработке файлы могут не сохраняться на диске). Функция всегда вернёт экземпляр, если что-нибудь не так, то расшифровка в поле errorMessage - например, файл зашифрован или формат не поддержан.
Собственно, всё. Теперь можно функцией getPlaintextString или getPlaintext получить плоский текст, или через getHtml сгенерировать Html-представление. Для более сложного анализа следует использовать другие функции, а также напрямую работать с деревом элементов, начинающемуся с поля content.
Форматы файловФорматы файлов задаются перечислением FileFormat. Для входного файла формат определяется автоматически при создании документа функцией createDocument, но есть отдельный хелпер FileFormatsHelper для быстрого определения формата. Не все из представленных в перечислении форматов поддерживаются SDK. Вот суммарная табличка с текущим состоянием.
| Формат | Подробнее | Поддержка |
|---|---|---|
| Html | HyperText Markup Language | Да |
| Mht | Mime Html | Да |
| Rtf | Rich Text Format | Да |
| Portable Document Format | Да, но не все типы картинок пока выделяются. Редко встречаются случаи, когда текст не определяется, хотя есть. | |
| Doc | MS Office 2003 | Да, но картинки не выделяются и не понимает вертикальное объединение ячеек таблицы. |
| Docx | Office Open XML | Да, также выделяются стили и страничные сегменты. |
| Odt | Open Document Format | Да |
| Xlsx | Office Open XML Spreadsheet | Да |
| Fb2/3 | Fiction Book | Да |
| Epub | Electronic Publication | Да |
| Text | Кодировки utf, dos и windows-1251 | Да |
| Csv | Comma-Separated Values | Да, оформляются одной таблицей UnitextTable. |
| Images | png, tiff, jpg и пр. | Оформляются одной картинкой UnitextImage. |
| Zip | Архив zip | Оформляются внутренними документами innerDocuments у документа. |
Ряд других форматов поддержан, но конвертер пока не может их переводить в конечный язык: Xls, DjVu, Msg (Outlook), Rar. Планируем поддержать их в следующих версиях.
Элементы структурно-текстового представленияБазовым классом всех элементов СТП является UnitextItem с полями:
Класс UnitextPlaintext определяет слитный фрагмент плоского текста, поле text содержит сам текст без переходов на новую строку, которые оформляются отдельными элементами UnitextNewline. Тип текста typ задаётся перечислением UnitextPlaintextType, и он может быть обычным SIMPLE, верхним индексом SUP или нижнем индексом SUB. Это может оказаться важно, так как для фрагмента "статья 21" если не учесть этот факт, то получим "статья 21", что неверно. При генерации в плоский текст такие случаи оформляются так, как это задано в параметрах генерации supTemplate и subTemplate (по умолчанию, шаблоном "<%1>", то есть обрамляется угловыми скобками).
Переход на новую строку оформляется через UnitextNewline, на новую страницу через UnitextPagebreak. Элементом UnitextMisc оформляется, в частности, горизонтальная линия (<hr />).
Важным элементом является контейнер UnitextContainer, содержащий другие элементы в своём списке children. У контейнера есть поле typ типа UnitextContainerType. Контейнеры можно встраивать в существующий документ функцией implantate, тем самым реализуя специфические подсветки в Html-представлении, в частности. У контейнера есть поле htmlStyle, в котором пользователь может установить дополнительные стили при выводе в Html.
Таблицы представлены классом UnitextTable, а ячейки таблиц - UnitextTablecell. Таблица виртуально является матрицей из rowsCount строк и colsCount столбцов. Ячейка может занимать одну или несколько клеток, причём если клеток несколько, то они должны быть прямоугольником в этих клетках. Поля colBegin, colEnd, rowBegin и rowEnd задают этот прямоугольник в терминах клеток матрицы, content - содержимое ячейки. Ячейки не пересекаются. Получить ячейку для клетки можно функцией getCell. Строки явным образом не оформляются. Вот так выглядит код перебора всех ячеек таблицы:
UnitextTable tab = ...
for (int r = 0; r < tab.RowsCount; r++)
for (int c = 0; c < tab.ColsCount; c++)
{
UnitextTablecell cel = tab.getCell(r, c); // получить ячейку для клетки [r, c]
if (cel == null) continue; // ячейка отсутствует
c = cel.ColEnd; // передвигаем указатель на последний столбец, занимаемый ячейкой
}
Отметим, что при анализе производится оптимизация таблиц. В частности, удаляются пустые столбцы, сама матрица из одного столбца и строки удаляется, оставляя только содержимое ячейки и другие действия. Таблицы, заданные в текстовой псевдографике, восстанавливаются в "нормальном виде". Таблица может иметь сложную структуру, объединяющую разные ячейки по вертикали и горизонтали. Для проприетарного формата Doc пока не удалось на 100% корректно восстанавливать вертикальные объединения. Для таких случаев устанавливается флаг mayHasError, чтобы можно было учесть этот факт при обработке.
Списки оформляются классом UnitextList, содержащий в items список элементов UnitextListitem. Элемент имеет содержимое content и может иметь внутренний список sublist, посредством которого реализуются вложенные списки.
Сноски UnitextFootnote имеют содержимое content и ряд специфических полей. В исходном файле они могут оформляться как в явном виде, так и в текстовом, когда в тексте место вставки отмечается типа <*>, а за параграфом после ряда тире или иных разделителей текст сноски идёт с новой строки после комбинации <*>. Такие случаи обнаруживаются и корректно обрабатываются.
Гиперссылка UnitextHyperlink содержит саму ссылку в поле href, а в content внутреннее содержимое.
Некоторые документы содержат аннотации (комментарии, примечания), которые оформляются классом UnitextComment. В принципе, аннотация может занимать произвольный участок, не вписывающийся в иерархическую модель элементов. Поэтому одна аннотация представляется двумя элементами - для начальной позиции и конечной позиции.
Картинки также выделяются и оформляются классом UnitextImage. Он содержит width и height, а также может содержать байтовый поток content с содержимым картинки. Не во всех случаях удаётся выделить этот байтовый поток. В частности, картинки не выделяются из проприетарного формата Doc, в некоторых случаях не удаётся из Pdf. Но в большинстве форматов они выделяются корректно. Тип картинки для потока можно определить функцией analizeFormat(null, content).
Стили и сегменты страниц структурно-текстового представленияСегмент страниц представляет собой слитный участок документа, страницы которого имеют одинаковые атрибуты, способ нумерации и колонтитулы. Он представлен классом UnitextPagesection, и если сегменты поддержаны для формата, то они помещаются в поле sections, а любой элемент ссылается на сегмент через pageSection. У сегмента есть элементы UnitextPagesectionItem, соответствующие колонтитулам: верхним, нижним, на чётных, нечётных страницах и пр.
Для некоторых форматов выделются ещё и стили, которые оформляются классом UnitextStyle. Стиль содержит информацию о шрифтах, цвете, габаритах, некоторые атрибуты абзаца. Если стили выделены, то их список находится в поле styles документа. Но с элементами UnitextItem они связаны не напрямую, а через так называемые стилевый фрагменты UnitextStyledFragment. Иерархия стилевых фрагментов, типы которых задаются перечислением UnitextStyledFragmentType, является самостоятельной структурой. Связь от UnitextItem к стилевому фрагменту (а, следовательно, и к стилю) осуществляется через функцию getStyledFragment(pos), которой нужно указать текстовую позицию в плоско-текстовых координатах BeginChar-EndChar.
Почему так сложно, а не прикрепить было стили к unitext-элементам? Дело оказалось в том, что в общем случае иерархия фрагментов не укладывается в иерархию unitext-элементов, и наоборот. Стилевой фрагмент может покрывать произвольное число элементов, причём не обязательно строго по границе. Равно как и unitext-элемент может содержать несколько стилевых фрагментов (например, если участок UnitextPlaintext имеет форматирование несколких отдельных слов, то каждый такой участок оформляется своим стилевым фрагментом). Поэтому связь многое-ко-многим осуществляется неявно через координаты плоского текста, на которые ототражаются обе иерархии.
Иерархия фрагментов близка структурной модели документа MS Word - на первом уровне иерархии блочные фрагменты типа PARAGRAPH и TABLE. Параграфы могут содержать INLINE. Таблицы могут содержать TABLECELL, которые в свою очередь могут иметь внутри блочные фрагменты. Корневой фрагмент, соответствующий всему содержимому документа (то есть содержащий общие элементы стилей), можно получить функцией getStyledFragment() без параметров или с параметром -1 у корневого unitext-элемента content или у самого документа. Если эта функция вернула null или список стилей пустой, то выделение стилей не поддержано (пока) для формата обрабатываемого файла.
Если стили выделены, то при выводе в Html документа или любого элемента функцией getHtml параметром outStyles можно управлять, использовать ли эти стили или игнорировать их.
Элементы тексто-графического представленияТексто-графический слой представлен страницей UnilayPage и прямоугольниками UnilayRectangle на страницах. Такой слой имеется не у всех форматов, но есть, в частности, у Pdf и DjVu. Данные форматы не содержат структурно-текстовое представление (СТП), как другие форматы документального типа. Поэтому СПТ для них воссоздаётся из этого низкоуровневого ТГП. Возможны некорректности при таком восстановлении. Например, может пропасть пробел или наоборот - разбить слово.
Встроенная оптимизация позволяет избавляться от колонтитулов и нумерации страниц, чтобы они не попадали в СТП. Но восстановить списки и таблицы не удаётся, особенно в случае отсканированного листа. Восстановление таблиц для нормально сгенерированных, а не распознанных Pdf стоит в планах.
Генерация плоского текстаПлоский текст (plain text) генерируется из структурно-текстового представления (СТП) путём объединения текстов из UnitextPlaintext. На уровне документа для этого используются функции getPlaintextString и getPlaintext. Аналогичные функции есть у каждого элемента UnitextItem для получания плоского текста, связанного только с этим элементом.
На результат генерации влияют многочисленные параметры, управляющие выводом специфических элементов и случаев. Например, как представлять в тексте переход на новую строку (0A или 0D0A), сноски и многое другое. Эти параметры задаются в классе GetPlaintextParam, экземпляр которого подаётся на вход вышеуказанным фукнциям генерации. Если использовать null в качестве экземпляра, то будут применяться значения по умолчанию.
Атрибут setPositions не влияет на результат генерации, но влияет на установку значений beginChar и endChar у всех элементов. По умолчанию эта опция отключена (false). Позиции плоского текста удобно использовать как универсальную систему координат, относительно которой можно производить разные действия. Например, выделять и подсвечивать нужный фрагмент (см. далее). Для документа можно получить плоский текст, обработать его и результат впоследствии использовать для встраивания в документ своих контейнеров UnitextContainer, пользуясь координатами плоского текста.
Визуализация в HtmlПодобно плоскому тексту, для всего документа или любого его элемента можно получить Html-представление с помощью функции getHtml. Параметры такой генерации задаются экземпляром класса GetHtmlParam, при null будут использоваться значения по умолчанию.
Такая визуализация может оказаться очень полезной для конечного пользователя, который сможет увидеть результат какой-либо обработки. Причём независимо от формата входного файла получается унифицированное представление, удобное для навигации по контенту и выделении нужных элементов.
В принципе, можно реализовать самим подобный вывод, если этот не устраивает по каким-либо причинам. Если же в целом вывод устраивает, но нужно вмешаться в генерацию каких-либо отдельных элементов или учесть частные случаи, то можно создать наследный класс от GetHtmlParam и переопределить у него функции callBefore и callAfter.
Постобработка и встраивание элементовSDK Unitext ориентируется на начальный этап анализа, когда нужно получить текст из файла, чтобы потом его обработать тем или иным образом. В зависимости от задачи, обработка может учитывать не только сам плоский текст, но и, например, таблицы, и анализировать не весь текст целиком, а тексты из конкретных ячеек. Например, если нужно извлечь информацию о товарах из тендерной документации, то в ней такая информация обычно располагается в таблицах. Поэтому в представлении Unitext входного файла нужно брать только таблицы UnitextTable, анализировать тексты заголовков, понимая, какая информация находится в тех или иных столбцах (если структура заранее неизвестна), и затем уже брать тексты в отдельных ячейках и производить с ними нужные действия. Вот так выглядит пример визуализации в Html для подобной задачи:
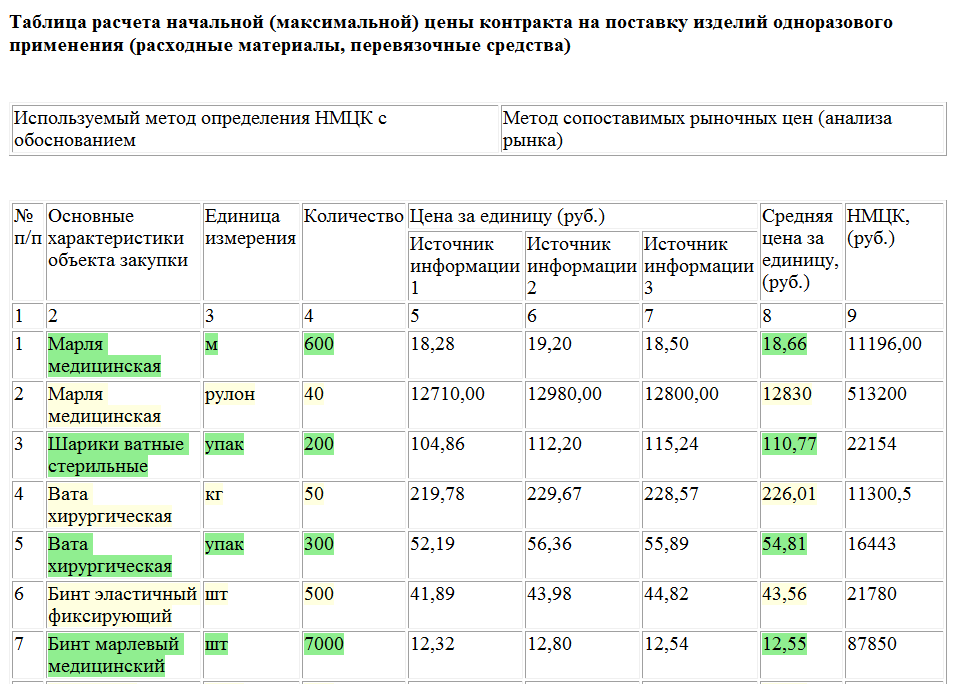
Здесь нужно было выделять номенклатурные наименования, единицы измерения, количество и средние цены, чтобы потом заполнять внешнюю базу данных. Для того, чтобы "раскрасить" нужные элементы (разумеется, в исходном файле этой раскраски нет), в документ с помощью функции implantate встраиваются контейнерные элементы UnitextContainer, которые содержат нужные стили для подсветки. Также навигацию можно осуществлять извне по Id этих элементов. Новый контейнер или экземпляр пользовательского наследного от UnitextContainer класса встраивается в существующее дерево СТП, включая в себя ряд узлов и само включаясь в нужный узел относительно позиций beginChar - endChar, которые и определяют, куда именно встроить новый узел. При этом некоторые существующий узлы могут быть разбиты на несколько, если граница встраиваемого элемента приходится на середину этих узлов. Есть ограничение на встраивание: нельзя корректно встроить в части смежных существующих узлов. Например, половину одной ячейки и половину соседней ячейки таблицы. В этом случае встраиваемый контейнер попадёт только в первый элемент и будет обрезан по его границе.
Структурирующий блокСтруктурирующий блок UnitextDocblock - это блок, содержащий тело, заголовок и, возможно, окончание. Таким блоком удобно представлять такие структурные элементы, как главы, параграфы, а для нормативных актов и договоров статьи, части, пункты, подпункты и пр. Тело структурирующего блока само может содержать аналогичные блоки, таким образом реализуется иерархия блоков. При этом для контейнеров UnitextContainer, принадлежащих блоку, устанавливаются типы typ, чтобы маркировать ключевые слова, наименования, нумерацию и пр.
Восстановление структурирующих блоков выходит за рамки SDK Unitext, так как в общем случае оно возможно после проведения лингвистического анализа плоского текста через SDK Pullenti (анализатором InstrumentAnalyzer, восстанавливающим иерархическую структуру нормативных документов). Для работы с нормативными документами есть специализированное SDK Pullenti Npa, в котором решается эта и ряд других специфических задач.
Но для некоторых форматов структурирующие блоки выделяются, когда есть структура глав. Для этого в параметрах создания докуменов нужно задать loadDocumentStructure = true. Пока это реализовано для форматов Html (теги h1, h2...) и FB2.
Оптимизация представленияВ SDK Unitext имеются средства, позволяющие оптимизировать структурно-текстовое представление (СТП). Включение и отключение тех или иных средств регулируется классом CorrectDocumentParam, являющимся полем correctParams. Оптимизация автоматически запускается сразу после получения СТП при создании createDocument и направлена на то, чтобы уменьшить количество элементов, а также преобразовать некоторые элементы в более подходящие. Например, в текстовых (и не только) файлах иногда таблицы задают через псевдографику, выравнивая пробелами - при оптимизации таблица будет восстановлена из множества UnitextPlaintext в UnitextTable.
Визуализация обработкиSDK Unitext в своём составе не содержит никаких средств визуализации, так как является кросс-платформенной и мультиязычной. Некоторая визуализация обработанных данных есть на сайте Pullenti в разделе Online-demo. Для пользователей Windows есть стенд, в котором можно провести анализ и получить результаты в наглядном виде.
Архив стенда Unitext.TestDesk нужно скачать с сайта, распаковать в директорию и запустить исполняемый exe-файл.
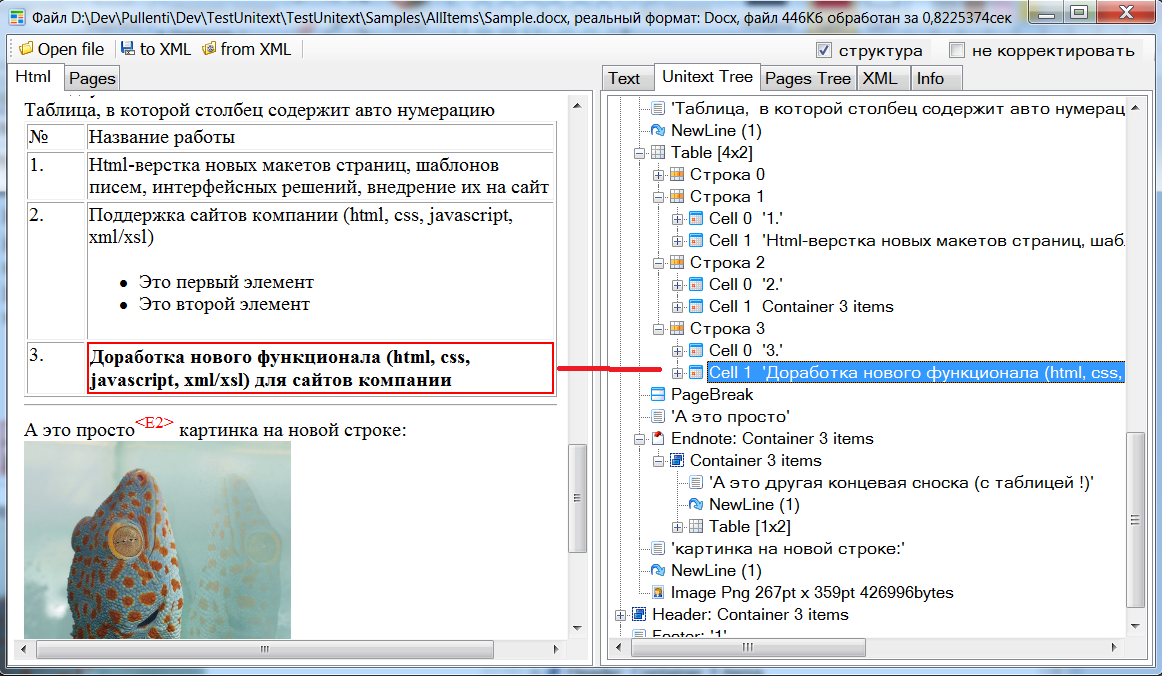
Кнопкой на панели загружаете файл. Слева на вкладке "Html" выводится результат работы getHtmlString, на вкладке "Pages" выводятся pages страницы тексто-графического представления (для Pdf и DjVu). Справа на вкладке "Text" результат работы getPlaintextString, на вкладке "Unitext Tree" в иерархическом виде элементы структурно-текстового представления Unitext, в "Pages Tree" в древовидном виде pages, на "XML" - вывод через getXml. Клик на дереве элементов справа приводит к выделению слева соответствующего элемента Html.