 Обзор SDK Pullenti Обзор SDK Pullenti
Обзор SDK Pullenti Обзор SDK PullentiSDK Pullenti предназначено для анализа неструктурированной информации - текстов на естественном языке. Поддержаны русский и украинский языки.
SDK Pullenti может быть полезно разработчикам информационных систем. SDK представлено функционально эквивалентным кодом на различных языках программирования: C#, Java, Python и Javascript. Исходный код вместе с этой документацией генерируется автоматически из исходного кода C# с помощью специально разработанного конвертера UniSharping. SDK работает на всех операционных системах и платформах, где поддержаны вышеуказанные языки. Свежую версию SDK можно скачать с сайта Pullenti.
Продукт Non-Commercial Freeware & Commercial Software, то есть бесплатен для некоммерческого использования и небесплатен для коммерческого.
SDK включает в себя морфологический анализ (POS-tagger), выделение именованных сущностей (NER), семантический анализ, а также набор дополнительных возможностей лингвистического анализа, полезных для практического применения.
SDK самодостаточно и не использует никаких сторонних модулей или библиотек (кроме стандартных из среды программирования конечного языка). SDK совсем не работает с диском или базами данных. Фактически SDK представляет собой сложную функцию, на вход которой подаётся текст в памяти, на выходе получается множество экземпляров специализированных классов. Откуда берутся тексты и как потом используются эти экземпляры - вопросы вне рамок предлагаемого SDK.
Отметим, что для решения практических задач одних только возможностей SDK Pullenti редко когда оказывается достаточно - приходится реализовывать дополнительную логику. Но эта реализация упрощается, если в качестве основы использовать возможности библиотеки.
Подключение SDK в C#Для использования SDK нужно добавить в своё решение (solution) проект Pullenti.Net.csproj для .NET Framework 4+ или Pullenti.Core.csproj для .NET Core 2+ в зависимости от платформы, а в своём конечном проекте поставить ссылку на данный проект.
Инициализация SDKПеред использованием функций SDK необходимо один раз произвести инициализацию. Она занимает несколько секунд, во время которых происходит распаковка словарей и подготовка данных.
Pullenti.Sdk.InitializeAll();
Если полная загрузка не требуется, то можно взять готовый код этого метода и вызывать только необходимое. Но рекомендуется всё-таки полная инициализация.
Простой примерКак быстро получить сущности: создать экземпляр лингвистического процессора Processor, вызвать его функцию Process() на анализируемом тексте SourceOfAnalysis. Результат AnalysisResult содержит список выделенных сущностей Entities.
// создаём экземпляр процессора со стандартными анализаторами
Processor processor = ProcessorService.CreateProcessor();
// запускаем на тексте text
AnalysisResult result = processor.Process(new SourceOfAnalysis(text));
// получили выделенные сущности
foreach (Referent entity in result.Entities)
Console.WriteLine(entity.ToString());
Более сложный пример, когда из текста нужно выделить все существительные и нормализовать их.
// перебираем токены
for (Token t = result.FirstToken; t != null; t = t.Next)
{
// нетекстовые токены игнорируем
if (!(t is TextToken)) continue;
// несуществительные игнорируем
if (!t.Morph.Class.IsNoun) continue;
// получаем нормализованное значение
string norm = t.GetNormalCaseText(MorphClass.Noun, MorphNumber.Singular);
Console.Write("\r\nNoun on position {0}: {1} ", t.BeginChar, norm);
}
Другие примеры использования см. в демонстрационном консольном примере, поставляемом вместе с SDK.
Общие рекомендации по обработкеВремя обработки текста не совсем линейно, поскольку для ряда сущностей по ходу составляются локальные словари, так что время получается чуть больше, чем линейное. К тому же обработка целиком происходит в памяти, которой может не хватить для многомегабайтного текста. Поэтому если нужно обработать много небольших текстов, то однозначно лучше их так и обрабатывать, не объединяя в один.
Если на входе большой текст, который фактически является суммой множества независимых текстов, то для обработки лучше его разделить на отдельные тексты (например, если известен разделитель), которые обрабатывать по отдельности.
Есть возможность направить обработку на сервер PullentiServer, запущенный в локальной сети. Данный сервер откомпилирован под .NET Core и работает на
всех платформах, запускаясь из командной строки как dotnet PullentiServer.dll. Используя его, пользователи SDK на Python
получат увеличение скорости раз в 20, а пользователи JavaScript - раз в пять. Для C# и Java это тоже может оказаться полезным, если по каким-либо
причинам трудоёмкий процесс нужно вынести вовне. Подробнее см. раздел "Обработка на сервере".
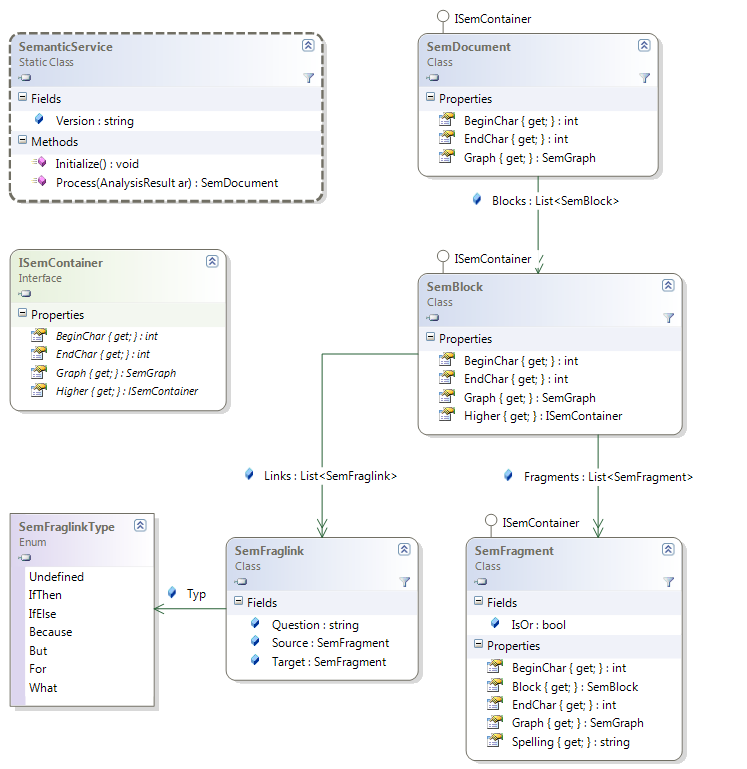
Именованные сущностиБазовым классом для сущностей является класс Referent (терминология частично взята из UIMA). Тип сущностей задаётся классом ReferentClass, который содержит набор описаний атрибутов Feature. Значение атрибута в сущности называется слотом Slot, то есть слот – это пара «атрибут, значение». Значение может быть как простой строкой, так и ссылкой на другую сущность. Обзор основных классов, связанных с сущностью, представлен на диаграмме.

Помимо значений атрибутов, сущность содержит список ссылок на участки TextAnnotation исходного текста, в которых эта сущность располагается. Исходный текст представляется классом SourceOfAnalysis, ссылки на него сокращённо называются Sofa (согласно UIMA).
В принципе, этой структуры достаточно для работы с сущностями. Но для облегчения дальнейшего анализа каждый тип сущностей оформляется своим классом, наследным от Referent. Такой класс содержит специфические свойства, которые просто оборачивают обращения к значениям соответствующих слотов. Например, сущность DateReferent имеет свойство int Year { get; set; }. Но на самом деле это просто обёртка, которая работает со слотом с именем YEAR в списке Slots из базовой сущности Referent. Итак, значения всех атрибутов всех сущностей хранятся в слотах базовой сущности.
Лингвистический процессорЛингвистический процессор представлен классом Processor. Он инкапсулирует в себе морфологический анализ и выделение сущностей. Выделение конкретных типов сущностей происходит в анализаторах, базовым классом которых является Analyzer. Последовательность обработки процессором определяется массивом Analyzers.
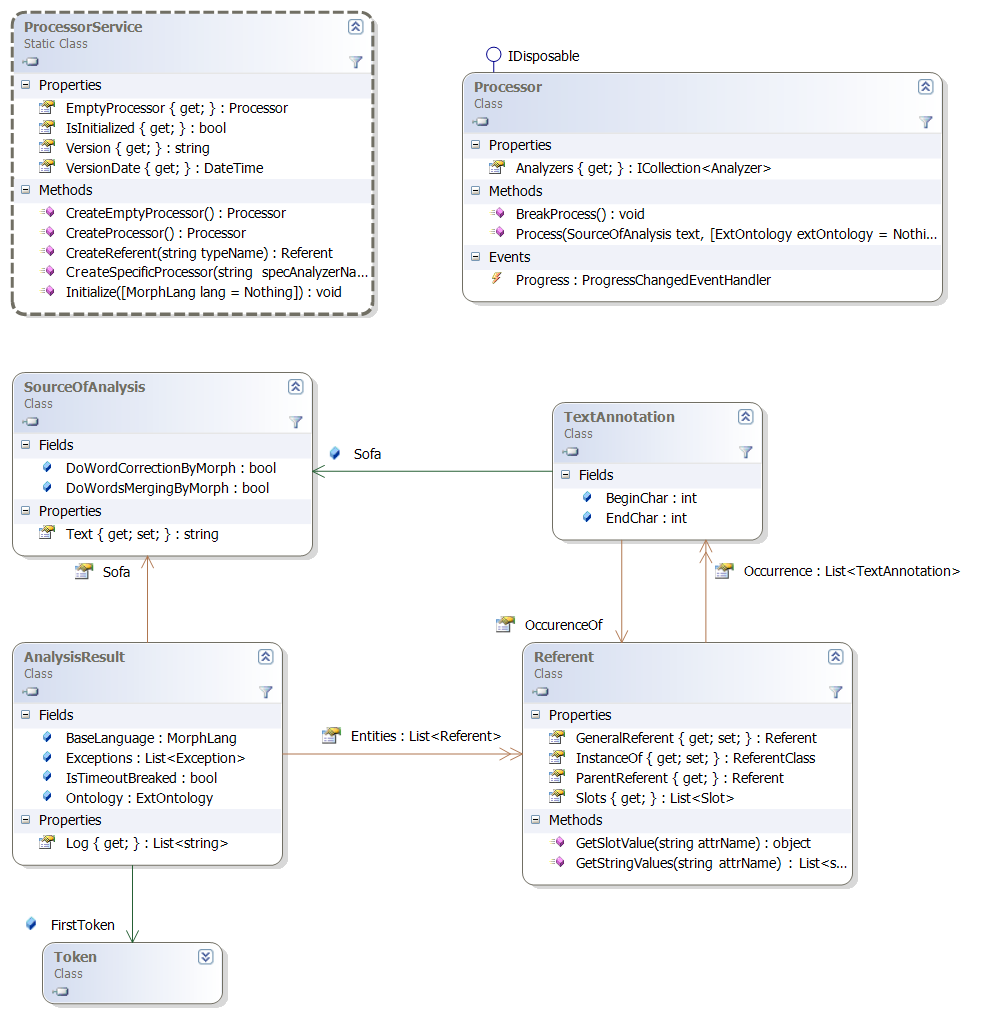
Статический класс ProcessorService содержит список доступных анализаторов Analyzers. Анализаторы подразделяются на стандартные и специфические, что что определяется их свойством IsSpecific. Стандартные анализаторы всегда вставляются по умолчанию в последовательность обработки процессора, создаваемого методом CreateProcessor(). Включение специфического анализатора нужно осуществлять либо явно через функцию AddAnalyzer у Processor, либо создавать экземпляр функцией CreateSpecificProcessor(…), указывая имя требуемого дополнительного анализатора. Это сделано потому, что специфические анализаторы рассчитываются на тексты определённой тематики и структуры. Например, анализатор заголовочной информации TitlePageAnalyzer включать в стандартную обработку было бы неправильно.
Чтобы выделить сущности из текста, сначала необходимо создать экземпляр процессора. Вот так создаётся процессор со стандартными анализаторами:
// создаём экземпляр процессора со стандартными анализаторами
Processor processor = ProcessorService.CreateProcessor();
// какие анализаторы содержит процессор
foreach (Analyzer a in processor.Analyzers)
Console.WriteLine(a.ToString());
Если в дополнение к ним нужно включить специфический анализатор, то его имя нужно указать в конструкторе:
// включение специфического анализатора для анализа заголовочной информацииProcessor processor = ProcessorService.CreateSpecificProcessor(TitlePageAnalyzer.ANALYZER_NAME);
При необходимости можно исключить какой-либо анализатор из списка Analyzers удалением элемента списка, или установив у него свойство IgnoreThisAnalyzer = true.
Ход анализа можно отслеживать через событие Progress системного типа ProgressChangedEventHandler:
// подписываемся на событие "бегунка"
processor.Progress += new ProgressChangedEventHandler(processor_Progress);
// пример обработки бегунка
void processor_Progress(object sender, ProgressChangedEventArgs e)
{
if (e.ProgressPercentage >= 0)
toolStripProgressBar1.Value = e.ProgressPercentage;
else
{
// если < 0, то это просто информационное сообщение
}
if (e.UserState != null)
{
toolStripLabelMessage.Text = e.UserState.ToString();
toolStrip1.Update();
}
}
Сам анализ производится функцией Process, которой на вход нужно подать исходный текст, оформленный классом SourceOfAnalysis:
string text = "...исходный анализируемый текст...";
// обёртка текста
SourceOfAnalysis sofa = new SourceOfAnalysis(text);
// запускаем анализ
AnalysisResult result = processor.Process(sofa);
// получили выделенные сущности
foreach (Referent entity in result.Entities)
Console.WriteLine(entity.ToString());
Результат AnalysisResult содержит список сущностей Entities, лог с кратким протоколом обработки Log и ссылку на первый токен FirstToken, который играет важное значение в деле дальнейшего анализа текста, если в этом есть необходимость.
АнализаторыКак говорилось выше, анализатор - это модуль выделения конкретных типов сущностей. Процессор содержит список анализаторов, которые применяются последовательно, а в самом начале вызывается морфологический анализ. Анализаторы подразделяются на стандартные, включаемые по умолчанию в создаваемые процессоры, и на специфические, включать которые нужно явно.
Стандартные анализаторы:
Специфические анализаторы:
ТокеныПри анализе исходный текст разбивается на токены в виде двунаправленного списка. В дальнейшем токены объединяются в метатокены, представляющие более крупные конструкции, в частности, сущности. Результирующий класс AnalysisResult содержит ссылку на первый токен FirstToken в списке токенов, представляющих исходный текст. На диаграмме представлена информация об основных токенах.
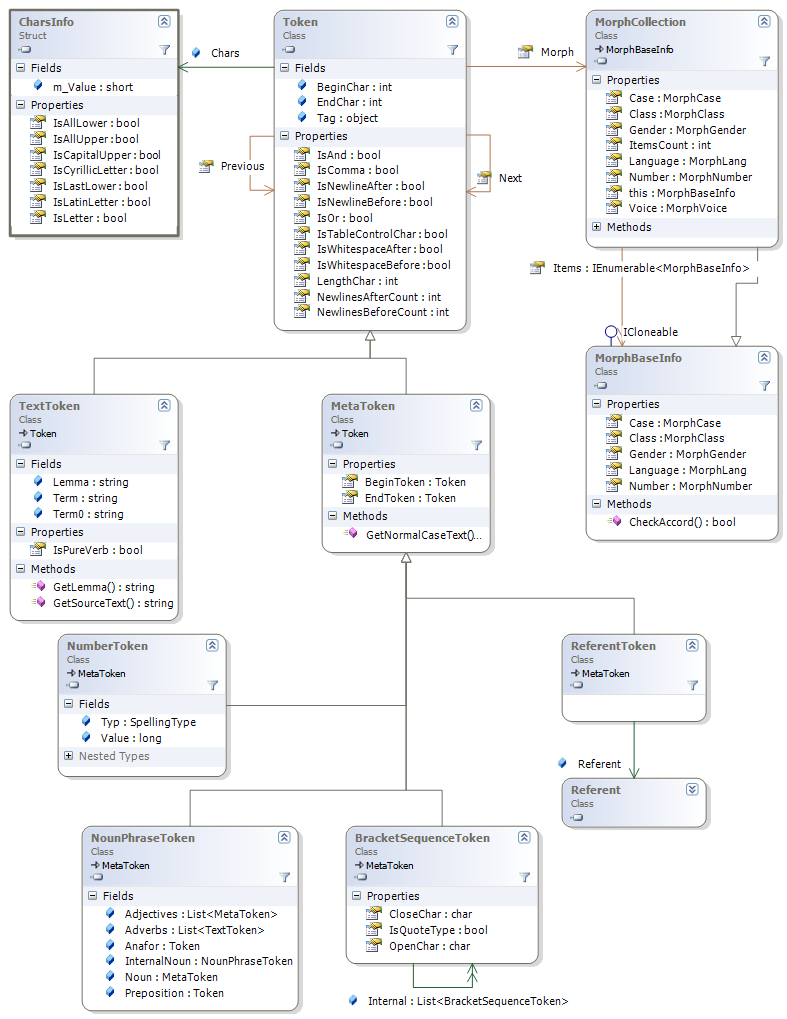
Базовым классом всех токеноы является класс Token. Свойства Previous и Next ссылаются на соседние токены, BeginChar и EndChar – позиции токена в символах в исходном тексте.
Chars – информация о символах токена: IsLetter – символы, IsAllLower – все символы в нижнем регистре и т.д.
Morph - морфологическая информация.
Основными наследными классами Token являются TextToken и MetaToken.
TextToken – это чистый исходный фрагмент текста с результатом морфологического анализа. Содержит информацию из MorphToken - результата предварительного морфологического анализа.
MetaToken – это токен, заменяющий диапазон токенов. Он как бы накрывает сверху другие токены, указывая свойствами BeginToken и EndToken на первый и последний из токенов, которые он как бы накрывает собой и выдавливает на нижележащий уровень. К классу метатокенов относятся NumberToken, представляющий число, ReferentToken, представляющий сущность, а также множество других элементов, используемых при анализе (некоторые из них описываются ниже).
Пусть, например, исходный текст такой: «это случилось в одна тысяча девятьсот девяностом году». Результирующая последовательность токенов будет состоять из трёх: первые два типа TextToken, и последний типа ReferentToken, ссылающийся на сущность DateReferent. В свою очередь ReferentToken покрывает 3 токена – TextToken («В»), NumberToken (1990) и TextToken («году»), а NumberToken под собой имеет 4 исходных текстовых токена, интерпретированных как одно число.

В процессе решения задач обработки текстов сложились хелперы и специфические метатокены, обрабатывающие и представляющие те или иные лингвистические объекты. К таким объектам относятся числовые значения в разных вариантах написаний, именные группы (существительные с возможными прилагательными, согласованными по морфологии), скобки и кавычки, концы предложений и другое. Для решения многих задач может оказаться достаточным набор предлагаемых возможностей, некоторые из которых описываются далее.
Числовые токеныКак целочисленные, так и действительные величины оформляются классом NumberToken, у которого значение представлено в поле Value строкового типа, для действительного числа разделителем всегда является точка. Поле Typ задаёт тип написания величины NumberSpellingType. Целочистенные величины типов Digit (явное число арабскими цифрами) и Words (прописью, например, «сто двадцать пять», «1-й») выделяются автоматически после морфологического анализа и встраиваются в последовательность токенов на начальном этапе обработки.
Всё остальное нужно выделять явно через функции NumberHelper.TryParse(...). Почему так? Да потому, что выделение или не выделение, скажем, римских цифр зависит от контекста. Например, в тексте присутствует «I» (английское ай), что может быть и инициал, и римская единица, и английское местоимение. Было бы неправильно сразу принимать какое-либо решение. Дополнительное выделение делается или не делается позже, на соответствующем этапе анализа. Например, анализатор персон PersonAnalyzer если после I идёт точка, то считает это инициалом, если перед I стоит имя, то считает римской цифрой (Пётр I), и т.д. Также нельзя на начальном этапе выделять дробные значения, так как точка или запятая между числами далеко не всегда является разделителем целой и дробной частей.
Рассмотрим пример, когда в тексте нужно выделять номера сессий (... на XXI-й сессии ...).
// перебираем токены
for (Token t = result.FirstToken; t != null; t = t.Next)
{
// может, номер задан явно цифрами или прописью
NumberToken num = t as NumberToken;
Token t1 = null; // ссылка на слово "сессия"
if (num != null) t1 = t.Next;
else
{
// пробуем выделить римское число
num = NumberHelper.TryParseRoman(t);
if (num != null)
{
// поскольку токен num не встроен в общую цепочку, а BeginToken\EndToken
// указывают на первый и последний токены цепочки, то следующий не num.Next,
// а именно num.EndToken.Next
t1 = num.EndToken.Next;
}
}
if (t1 == null || num == null)
continue;
if (!t1.IsValue("СЕССИЯ"))
continue;
// нашли
Console.Write("\r\nSession {0} on position {1}", num.Value, t.BeginChar);
t = t1;
}
В этом примере можно поступить по-другому: сначала проверять t.IsValue(“СЕССИЯ”), а затем пытаться выделить римскую цифру в обратном порядке через TryParseRomanBack.
У NumberToken есть свойство IntValue, и если оно не Null, то значение из Value является целочисленным и помещается в 32 бита (это сделано потому, что в Javascript отсутствуют 64-х разрядные целые, а мы хотим поддерживать разные языки). Действительное значение (double) можно получить через свойство RealValue, а если оно NaN, то не удалось преобразовать строку из Value в double.
Для надёжных преобразований между string и double рекомендуется использовать методы StringToDouble и DoubleToString, которые работают одинаковым образом на всех языках программирования независимо от locale-настроек операционной системы.
Функция TryParseAge выделяет конструкции типа «20-летний», TryParseAnniversary разные годовщины типа «XX-й годовщины», GetNumberAdjective позволяет преобразовать любое число в его словесное представление в нужном роде и числе (например, 34 для ж.р. => «ТРИДЦАТЬ ЧЕТВЕРТАЯ»). Подробности см. описание NumberHelper.
Измеряемые величиныПод изменяемыми величинами мы понимаем числовое значение или диапазон с единицами измерения. Например, "Давление на выходе: от 62 до 65 кгс/см2", "Мощность - минимальная 1 Вт, максимальная 4 Вт.", "Габариты: (длина/ширина/высота): 34.4 см x 10.4 см x 14.0 см", "относительная влажность воздуха до 70% при t = 25°С". Наименование также входит в величину. Такие конструкции оформляются сущностью MeasureReferent, а сами единицы измерения сущностью UnitReferent.
В старых версиях SDK Pullenti для этого был класс NumberExToken с сильно ограниченным функционалом. Сейчас мы от него отказываемся, в пользу MeasureReferent - старый класс больше не поддерживается и временно оставлен для совместимости.
Анализатор MeasureAnalyzer является специфическим, то есть не встраивается по умолчанию в процессор, а его нужно добавлять туда явно. Если же процессор не содержит MeasureAnalyzer, но требуется проверить для Token, начинает ли он такую измеряемую величину, то следует воспользоваться функцией ProcessReferent, которую можно использовать для любого типа сущностей.
for (Token t = ar.FirstToken; t != null; t = t.Next)
{
// смотрим, выделяется ли сущность с токена t
ReferentToken rt = t.Kit.ProcessReferent(MeasureAnalyzer.ANALYZER_NAME, t);
if (rt != null)
{
MeasureReferent mef = rt.Referent as MeasureReferent;
// производим нужные действия
...
// позицию на последний токен сущности
t = rt.EndToken;
}
}
Отметим, что денежная сумма формально также является измеряемой величиной, однако она оформляется отдельной сущностью MoneyReferent и всегда выделяется стандартным анализатором MoneyAnalyzer.
Скобки и кавычкиПроблемы выделения последовательностей, обрамляемых кавычками и скобками, возникают, когда забывают ставить закрывающие скобки или несколько закрывающих скобок сливаются в одну при вложенных друг в друга последовательностях. Поскольку кавычки часто используются для задания имён и наименований, то работа с ними выделена в отдельный хелпер.

Хэлпер работает со скобками и кавычками в различных их представлениях. Метатокен BracketSequenceToken может иметь список Internal внутренних групп кавычек. Например, ОАО «Компания «Пупкиных» - одна последовательность «Компания Пупкиных» имеет вложенную подпоследовательность «Пупкиных».
Обрамлённые скобками и кавычками последовательности выделяются функцией BracketHelper.TryParse. Дополнительные атрибуты задаются битовой маской из значений типа BracketParseAttr.
Функция GetNormalCaseText возвращает внутренний текст, при этом первая именная группа приводится к именительному падежу. Например, для текста «Турбинных двигателей, вращающих …» нормализация даст «ТУРБИННЫЕ ДВИГАТЕЛИ, ВРАЩАЮЩИЕ …» или «ТУРБИННЫЙ ДВИГАТЕЛЬ, ВРАЩАЮЩИЙ …».
Именные группыИменная группа - это существительное с возможными прилагательными, согласованными по числу и падежу. Например, "именная группа", "информационно-поисковая аналитическая система". Она реализуется классом NounPhraseToken, который содержит корень Noun и список прилагательных Adjectives, возможно, пустой.
Все эти элементы сами являются метатокенами (наследные классы от MetaToken), так как могут состоять из нескольких текстовых токенов. Например, Noun «девочка-подросток» или Adjective «сильно-действующий». Может быть ссылка на текстовой токен, представляющий анафору, и на предлог: «от её старшего брата» - Preposition: «от», Anafor: «её», Adjective: «старший», Noun: «брат».
Может быть внутренняя именная группа InternalNoun. Например, у «по настоящим на данный момент представлениям» базовая группа «НАСТОЯЩЕЕ ПРЕДСТАВЛЕНИЕ», а внутренняя - «ДАННЫЙ МОМЕНТ».
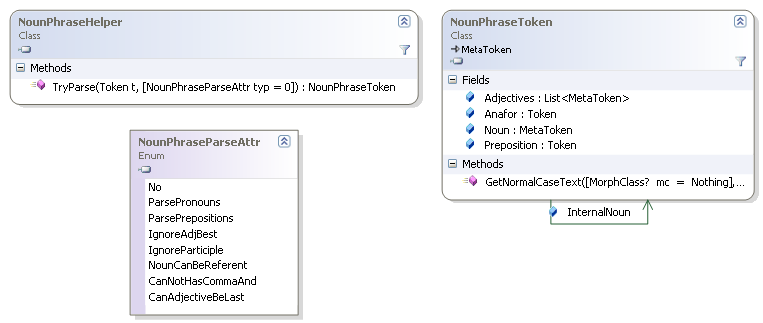
Именные группы выделяются функцией NounPhraseHelper.TryParse. Дополнительные атрибуты задаются битовой маской из значений типа NounPhraseParseAttr. Пример выделения всех именных групп и составления словаря частоты их встречаемости.
Dictionary stat = new Dictionary();
for (Token t = result.FirstToken; t != null; t = t.Next)
{
NounPhraseToken npt = NounPhraseHelper.TryParse(t);
if (npt == null) continue;
// нормализуем к единственному числу
string normal = npt.GetNormalCaseText(null, true);
if (!stat.ContainsKey(normal)) stat.Add(normal, 1);
else stat[normal]++;
// перемещаемся в конец метатокена
t = npt.EndToken;
}
Отметим, что если не перемещаться в конец метатокена t = npt.EndToken, то для текста «информационная система» сначала выделится «информационная система», а затем просто «система».
Как и у любого токена, NounPhraseToken имеет свойство Morph с уточнённой морфологической информацией. На этапе морфологического анализа у TextToken морфология вычисляется без учёта контекста, и Morph.Items содержит все морфологические варианты, поступающие от POS-Tagger-а. Для именной группы лишние несогласованные варианты отбрасываются и оставляются только согласованные.
Функция GetNormalCaseText возвращает нормализованный вариант всей группы, а не отдельных слов. Например, для фрагмента «информационных систем» у каждого токена по отдельности эта функция вернёт «ИНФОРМАЦИОННЫЙ» и «СИСТЕМА», а для всей именной группы GetNormalCaseText(null, MorphNumber.Plural) = «ИНФОРМАЦИОННЫЕ СИСТЕМЫ», GetNormalCaseText(null, MorphNumber.Singular) = «ИНФОРМАЦИОННАЯ СИСТЕМА».
Аналогично именным группам, есть метатокены и хелперы для глагольных групп VerbPhraseToken / VerbPhraseHelper, для предложных групп PrepositionToken / PrepositionHelper и для союзных групп ConjunctionToken / ConjunctionHelper.
ХелперВ ходе решения практических задач ряд функций анализа выносились в отдельные хелперы, некоторые из которых описывались выше. Мелкие фукнции собирались в статическом классе MiscHelper. Перечислим некоторые из наиболее полезных фукнций.
Другие функции см. в описании класса MiscHelper.
Словарь терминовЕсли нужно проверить для токена Token некоторое слово (с учётом морфологических вариантов), то для этого у него есть функция IsValue. Однако если нужно проверить много ключевых слов, то циклический вызов этой функции сильно снизит производительность. Для таких случаев предназначен класс TerminCollection.
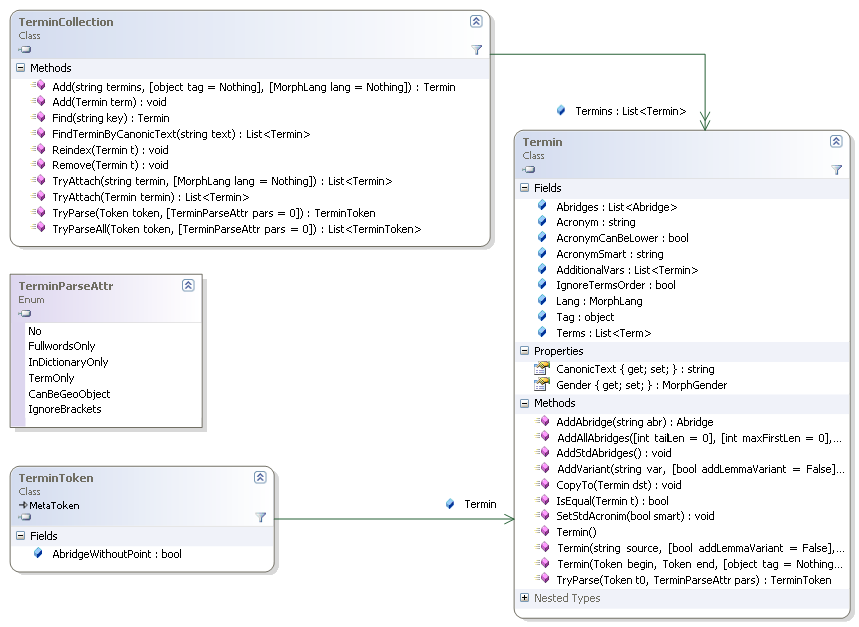
Принцип работы следующий: в словарь добавляются термины (как при начальной инициализации, так и на этапе анализа), и можно быстро проверять на их вхождение в последовательности токенов. Термин Termin – это конструкция, содержащая не только слова и их словосочетания, но и всевозможные сокращения, аббревиатуры и другие варианты написаний. В качестве примера рассмотрим фрагменты кода, которыми формируется один из внутренних словарей для задания ключевых слов анализатора, выделяющего улицы (полный текст см. в коде у элемента Pullenti\Ner\Address\Internal\StreetItemToken).
TerminCollection m_Ontology = new TerminCollection();
Termin t;
t = new Termin("УЛИЦА") { Tag = StreetItemType.Noun };
t.AddAbridge("УЛ.");
m_Ontology.Add(t);
t = new Termin("ВУЛИЦЯ") { Tag = StreetItemType.Noun, Lang = MorphLang.UA };
t.AddAbridge("ВУЛ.");
m_Ontology.Add(t);
Отметим, что здесь возможные сокращения задаются явно. Также для разных языков можно добавлять термины в один и тот же словарь, в зависимости от языка текущего текста будут использоваться только соответствующие языку записи. Поле Tag используется произвольным образом, здесь оно содержит некоторый внутренний классификатор.
t = new Termin("ПРОСПЕКТ") { Tag = StreetItemType.Noun };
t.AddAbridge("ПРОС."); t.AddAbridge("ПРОСП."); t.AddAbridge("ПР-Т");
t.AddAbridge("ПР-КТ"); t.AddAbridge("П-Т"); t.AddAbridge("П-КТ");
m_Ontology.Add(t);
t = new Termin("ВОЕННЫЙ ГОРОДОК") { Tag = StreetItemType.Noun };
t.AddAbridge("В.ГОРОДОК"); t.AddAbridge("В/Г"); t.AddAbridge("В/ГОРОДОК"); t.AddAbridge("В/ГОР");
m_Ontology.Add(t);
t = new Termin("ПРОМЫШЛЕННАЯ ЗОНА") { Tag = StreetItemType.Noun };
t.AddVariant("ПРОМЗОНА");
m_Ontology.Add(t);
Здесь отметим, что AddVariant задаёт не сокращение, а именно дополнительный способ написания.
t = new Termin("ВЕРХНИЙ") { Tag = StreetItemType.StdAdjective };
t.AddAbridge("ВЕРХН."); t.AddAbridge("ВЕРХ.");
t.AddAbridge("ВЕР."); t.AddAbridge("В.");
t.AddVariant("ВЕРХНІЙ");
m_Ontology.Add(t);
А здесь украинский способ просто добавляется как вариант к русскому – так тоже можно.
t = new Termin("АВТОДОРОГА") { Tag = StreetItemType.Noun };
t.AddVariant("ФЕДЕРАЛЬНАЯ АВТОДОРОГА"); t.AddVariant("АВТОМОБИЛЬНАЯ ДОРОГА");
t.AddVariant("ТРАССА"); t.AddVariant("АВТОТРАССА"); t.AddVariant("ФЕДЕРАЛЬНАЯ ТРАССА");
m_Ontology.Add(t);
Обратите внимание: термин добавляется в словарь Add после полного своего определения. Это важно, так как в момент своего добавления все его способы представления добавляются во внутренние словари этого TerminCollection, и последующие изменения t не будут учитываться (впрочем, можно вызвать функцию Reindex).
Это был пример статического словаря, формируемого один раз при инициализации Sdk и в дальнейшем не изменяемого. Но можно формировать такие словари динамически на основе анализа текущего текста, добавляя термины динамически. Именно так анализатор выделения персон составляет локальный список фамилий и учитывает эту информацию при выделении.
Основная функция при выделении в потоке токенов – TryParse. В случае удачи вернёт TerminToken – метатокен, задающий границы начала и конца термина в тексте (BeginToken - EndToken) и ссылающийся на термин Termin. Если терминов может быть привязано несколько, то берётся самый длинный из возможных. Если нужно получить все варианты, то используйте функцию TryParseAll, возвращающую список.
Внешняя онтология (словари)Выделение сущностей основано на правилах. Для некоторых типов сущностей можно подгружать внешний словарь (условно назовём его внешней онтологией), содержащий описания внешних сущностей. В этом случае анализатор при выделении будет пытаться привязываться к элементам этого словаря, устанавливая поле OntologyItems у экземпляров Referent. Такой словарь реализуется классом ExtOntology со списком элементов ExtOntologyItem, которые нужно добавить функциями Add или AddReferent. Словарь может содержать элементы любых поддерживаемых типов сущностей.

Рассмотрим пример. Пусть есть список сотрудников, которых нужно искать в текстах.
// создаём словарь-онтологию
ExtOntology personOntos = new ExtOntology();
Каждого сотрудника можно добавить 2-мя способами: в виде текстового описания или в виде готовой сущности. Если у нас не выделены по отдельности Имя-Фамилия-Отчество, то добавляем неструктурированное описание (точкой с запятой разделяются несколько описаний, если таковые имеются):
string desciption = "Иванов Иван Иванович;Ivanov Ivan";
ExtOntologyItem it = personOntos.Add("любой Id", "PERSON", desciption);
Если же информация заранее структурирована, то можно сразу создать сущность и добавить её в словарь:
PersonReferent person = new PersonReferent();
string firstName = "ИВАН", lastName = "ИВАНОВ", middleName = "ИВАНОВИЧ";
person.AddSlot(PersonReferent.ATTR_FIRSTNAME, firstName, false);
person.AddSlot(PersonReferent.ATTR_MIDDLENAME, middleName, false);
person.AddSlot(PersonReferent.ATTR_LASTNAME, lastName, false);
ExtOntologyItem it = personOntos.AddReferent("любой Id", person);
Полученный словарь нужно подать вторым параметром на вход процессору при обработке текста:
AnalysisResult res = proc.Process(new SourceOfAnalysis(...), personOntos);
В результирующем списке сущностей Entities те из них, которые удалось привязать к элементам внешней онтологии, будут содержать непустые списки на эти элементы OntologyItems. Теоретически сущность может привязаться более чем к одному элементу словаря, поэтому это именно список.
Отметим, что наличие такого словаря не только даёт привязку, но и может повысить качество выделения сущностей, поскольку в сомнительных случаях анализатор руководствуется дополнительной информаций для принятия решения. Но если словарь будет большим, что это может увеличить время аналиа. А вообще-то анализаторы неплохо справляются и без этого словаря...
Аналитический контейнерДля каждого текста на начальной стадии его обработки создаётся так называемый аналитический контейнер AnalysisKit, информацию из которого можно использовать при анализе. Каждый токен ссылается на контейнер через свойство Kit. Контейнер последовательность токенов (FirstToken – ссылка на первый), статистику по токенам StatisticCollection и множество вспомогательных данных, используемых в основном внутренним образом.
Через функцию EmbedToken происходит встраивание метатокенов в основную последовательность токенов. Например, пусть для удобства анализа нужно встроить именные группы в последовательность.
for (Token t = result.FirstToken; t != null; t = t.Next)
{
NounPhraseToken npt = NounPhraseHelper.TryParse(t);
if (npt == null) continue;
// встраиваем
t.Kit.EmbedToken(npt);
// теперь вместо npt.BeginToken (=t) ... npt.EndToken в последовательности один npt
t = npt;
}
Рассмотрим текст «на маленьком плоту сквозь». Изначально здесь 4 токена: FirstToken = «на» ⟷ «маленьком» ⟷ «плоту» ⟷ «сквозь». Стрелками показаны ссылки Previous и Next на соседние токены слева и справа. После выделения npt до его встраивания npt.Next = npt.Previous = null, а npt.BeginToken = «маленьком» и npt.EndToken = «плоту». После встраивания получаем 3 токена: FirstToken = «на» ⟷ «МАЛЕНЬКИЙ ПЛОТ» ⟷ «сквозь», причём BeginToken и EndToken у встраиваемого npt продолжают указывать на токены, которые покрыл npt, так что в случае необходимости до них всегда можно добраться.
Морфологический анализМорфологический анализ в SDK Pullenti - это собственный POS-tagger, который для каждой словоформы предлагает всевозможные морфологические варианты вне зависимости от контекста этой словоформы. Выбор из них "правильного варианта" может производиться на следующих этапах анализа. Поддерживаются русский, украинский и английский язык, для несловарных (неизвестных) слов выдаются вероятные варианты. Для токена предлагается вариант леммы (нормальная форма). Есть функция получения для нормальной формы слова всех вариантов словоформ для перевода в нужный род, падеж и число.
При начальном разбиении текста на токены делается лексикографическая корректировка. Например, если в слове на кириллице одна буква заменена на латинскую, аналогичную по внешнему виду, то производится соответствующая замена. Также корректируются буквы с ударениями, замена апострофа на «ъ» (об`явление), «ё» на «е» и множество экзотических случаев. Например, Sdk распознаёт ситуацию, когда букву Ы пишут через Ь и I, а в слове "ПPИКА3" буква «P» на латинице, а в конце цифра тройка.
Класс MorphologyService с функциями морфологии содержит ряд полезных функций. Если морфология не используется отдельно от анализа в рамках лингвистического процессора, то явный вызов MorpholodyService.Process не потребуется - это делается внутри Processor.Process. Также не потребуется работа с MorphToken, информация откуда переходит в TextToken.
На диаграмме показаны основные классы, связанные с морфологией.

Полезными здесь являются MorphClass - часть речи, MorphGender - род, MorphNumber - число, MorphCase - падеж, а также кортеж этих свойств MorphBaseInfo. Контейнер вариантов MorphCollection содержит список Items из элементов MorphBaseInfo. Каждый токен Token имеет свойство Morph с типом этого контейнера, хотя, возможно, с пустым числом элементов (например, для знака пунктуации).
Текстовой токен TextToken в этом поле Morph в списке имеет элементы с расширенний морфологической информацией, представленной наследным от MorphBaseInfo классом MorphWordForm. В частности, он содержит нормализованную по падежу форму NormalCase и полностью нормализованную форму NormalFull - мужской род единственное число. Например, для словоформы "исходных" падежная нормализация - "ИСХОДНЫЕ", а полная - "ИСХОДНЫЙ". Помимо этого, MorphWordForm содержит дополнительные морфологические характеристики MorphMiscInfo в свойстве Misc, признак словарности и др.
Дериватные группы и супернормализацияДериватная группа (ДР) - это набор однокоренных словоформ различных частей речи и даже языков. Например, "ПРОГРАММИРОВАНИЕ", "ПРОГРАММИСТ", "ПРОГРАММИСТКА", "ПРОГРАММИСТСКИЙ", "ПРОГРАММНО", "ПРОГРАМИРОВАТЬ", "ПРОГРАММИРУЮЩИЙ", "ПРОГРАММИРУЕМЫЙ" и т.д. Реализуется классом DerivateGroup, который содержит список Words словоформ DerivateWord. Каждая словоформа содержит лемму Spelling, часть речи Class, язык Lang и ряд других признаков. По этим характеристикам в группе можно найти нужную словоформу.
Список таких ДГ встроен в SDK, в настоящий момент там около 14000 групп.
Найти ДР можно функцией FindDerivates, подав на вход слово в верхнем регисте и нормальной форме. В случае нахождения функция вернёт список подходящих групп, содержащих данное слово. Для задачи перевода слова в другую часть речи можно сразу использовать функцию GetWordClassVar.
Данный функционал можно использовать для более сложной нормализации текстов, чем морфологическая лемматизация (приведение слов к леммам). Если каждую словоформу переводить в лемму, а для неё находить ДГ и брать в ней первое слово, то нормализация получится более сложной. Вот пример кода, решающий эту задачу через механизм ДР:
AnalysisResult ar = ...; // результат обработки процессором
StringBuilder norm = new StringBuilder(); // для записи нормализованного текста
for (Token t = ar.FirstToken; t != null; t = t.Next)
{
if (t.Previous != null && t.Previous.IsWhitespaceBefore) norm.Append(" ");
if (t is NumberToken)
{
// нормализуем числовые значения
norm.Append((t as NumberToken).Value);
continue;
}
if (t is ReferentToken)
{
// сущности выводим нормализованными
norm.Append((t as ReferentToken).Referent.ToString());
continue;
}
// текстовой токен
TextToken tt = t as TextToken; if (tt == null) continue;
if (tt.LengthChar < 2) norm.Append(tt.Term);
else
{
// берём лемму словоформы
var lemma = tt.Lemma;
// ищем для леммы дериватную группу
List<DerivateGroup> groups = DerivateService.FindDerivates(lemma);
if (groups != null && groups.Count > 0)
lemma = groups[0].Words[0].Spelling; // если нашли, то берём первое слово у первой ДГ
norm.Append(lemma);
}
}
Отметим, что ДГ содержит не только слова одного языка, но и аналогичные слова других языков, в частности, украинского и немного английского. И вышеуказаная "супернормализация" позволяет решать, например, задачу поиска плагиата в русском и украинском тексте, если повторения ищутся в обоих нормализованных текстах.
Но и это не всё. ДГ также содержит модель управления ControlModel, где есть информация о предлогах и падежах для семантических связей. Обычно модели задаются на уровне отдельных слов, но нам представляется, что лучше задавать их на уровне группы, так как модели в основном совпадают для слов группы. Эта информация используется при проведении поверхностного семантического анализа. Для построения отдельных семантических связей SemanticLink в классе SemanticHelper есть функция TryCreateLinks.
Семантический анализСемантический анализ производится через функции класса SemanticService. В отличие от морфологии, этот анализ не включается по умолчанию в обработку лингвистическим процессором Processor, поскольку не нужен в большинстве практических случаев. В частности, не используется при выделении сущностей. Задействовать его можно функцией SemanticService.Process, подавая на вход не текст, а результат обработки лингвистическим процессором AnalysisResult, который провёл морфологический анализ и выделил сущности. Тогда семантический процессор попытается из этого результата построить семантический граф.
Processor proc = ProcessorService.CreateProcessor();
AnalysisResult ar = proc.Process(new SourceOfAnalysis(txt));
SemDocument doc = SemanticService.Process(ar);
Данное направление сейчас находится в состоянии разработки. Для несложных случаев граф строится, но многое ещё предстоит сделать для вложенных причастных оборотах, чередуемых с многоуровневыми однородными членами, и других сложных конструкций. Несмотря на это, отдельные разработчики используют семантику Pullenti as-is в своих проектах, поэтому она включена в даннную документацию.
Под семантическим анализом в SDK Pullenti понимается представление текста естественного языка в виде графа, модель которого описывается ниже. Это представление само по себе не является самоцелью, а служит задаче проведения дальнейшего анализа на качественно другом уровне, на котором снижается зависимость от проблем, связанных с языковой вариативностью. Скажем, «Петя пошёл в школу», «Пошедший в школу Петя», «Петя, который пошёл в школу», «Школа, в которую пошёл Петя», «…Петя. Он пошёл в школу» и т.д. должны приводить к одному и тому же представлению. Отметим, что некоторые аспекты при таком представлении могут теряться, например, эстетические. Но это - модель, и она имеет свои ограничения.
Для ряда задач (например, полнотекстового поиска) эффективным является лексическая нормализация – приведение слов к нормальной форме. В нашем случае речь идёт о «семантической нормализации» - нормализация не только слов, но и их отношений. Наше представление – это два отдельных графа: семантический и фрагментный.
Семантический граф (СГ) – это граф SemGraph из однородных узлов SemObject и связей между ними SemLink. Узел соответствует слову или комбинации слов (например, именованной сущности). Связь отвечает на некоторый вопрос, направленный к узлу основания связи. Выделяются некоторые стандартные типы связей SemLinkType: агенс (кто действует), пациенс (кем действуют), детализация и др. Отметим что не каждое слово текста преобразуется в свой узел, так как служебные и структурирующие слова трансформируются в связи или атрибуты узлов. Например, «пошёл в школу» предлог «в» не становится узлом, а оформляется связью между узлами «идти» и «школа».

Фрагментный граф (ФГ) – это граф из других однородных узлов и связей, где каждому узлу соответствует некоторый фрагмент SemFragment. Обычно для простого предложения получается один узел, а для сложного – несколько узлов, между которыми устанавливаются связи SemFraglink типа SemFraglinkType «если то», «если иначе», «однако», «потому что», «диалог» и др. Каждый узел ФГ содержит свой СГ в поле Graph, то есть узлы ФГ как бы накрывают сверху узлы СГ, но по связям эти два графа независимы друг от друга. Узлы ФГ как бы содержат внутри себя маленькие подграфы. Эти СГ фрагментов чаще всего по связям замкнуты внутри своих фрагментов, хотя возможны связи и с узлами СГ других фрагментов.
В нашей модели нет понятия предложения, так как это условное понятие (на наш взгляд). Например, «Петя пошёл в школу, Маша пошла в детский сад.» и «Петя пошёл в школу. Маша пошла в детский сад.» с точки зрения ФГ в обоих случаях есть два узла, и не важно, сколькими предложениями это оформлено. В Pullenti принята иерархия: «весь текст SemDocument – блок текста SemBlock – фрагмент SemFragment», где под блоком понимается относительно независимый участок, например, абзац. Впрочем, это деление тоже условно, и ориентироваться нужно на фрагменты. Итак, цель нашего представления – избавиться от служебных слов (предлогов, союзов, местоимений, частиц, некоторых наречий), нормализовав и структурировав оставшееся как на уровне семантических связей, так и на уровне связей фрагментов.
Визуализация данныхSDK Pullenti в своём составе не содержит никаких средств визуализации, так как является кросс-платформенной и мультиязычной. Некоторая визуализация обработанных данных есть на сайте Pullenti в разделе Online-demo. Для пользователей Windows есть стенд, в котором можно провести анализ и получить результаты в наглядном виде.
Архив стенда Pullenti.TestDesk нужно скачать с сайта, распаковать в директорию и запустить исполняемый exe-файл.
В левом окне задаётся текст (включить режим редактирования можно кнопкой слева на панели) или загружается из файла. Результат обработки AnalysisResult отображаются на вкладках справа. По умолчанию, обработка производится всеми стандартными анализаторами, то есть процессором из функции CreateProcessor. Специфический анализатор можно добавить из выпадающего списка на панели, и тогда процессор будет из функции CreateSpecificProcessor.
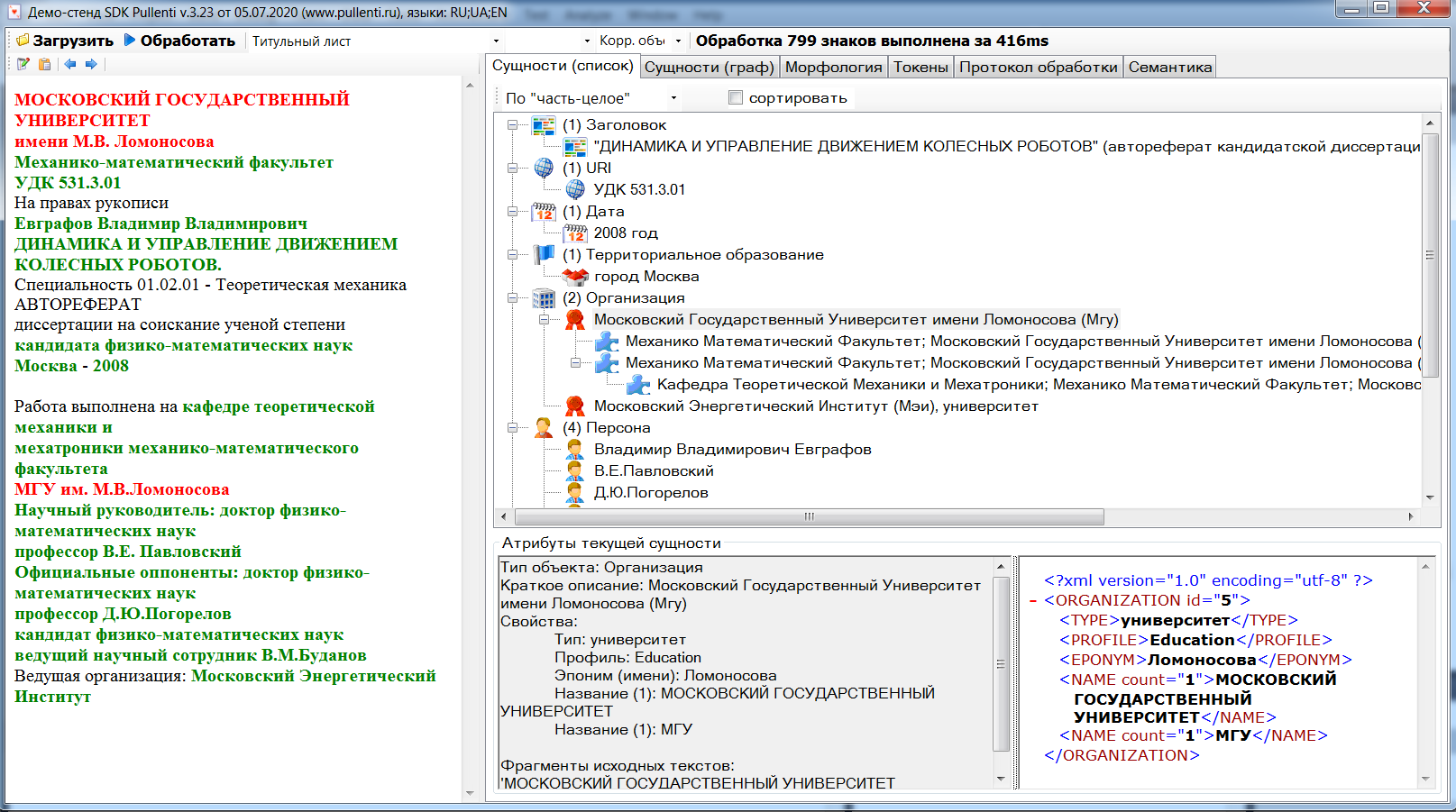
На первой вкладке выводится список сущностей Entities, который круппируется по типу сущности и по иерархии ParentReferent. Для текущей сущности внизу выводятся её атрибуты Slots, а в исходном тексте подсвечиваются соответствующие сущности текстовые фрагменты Occurrence.
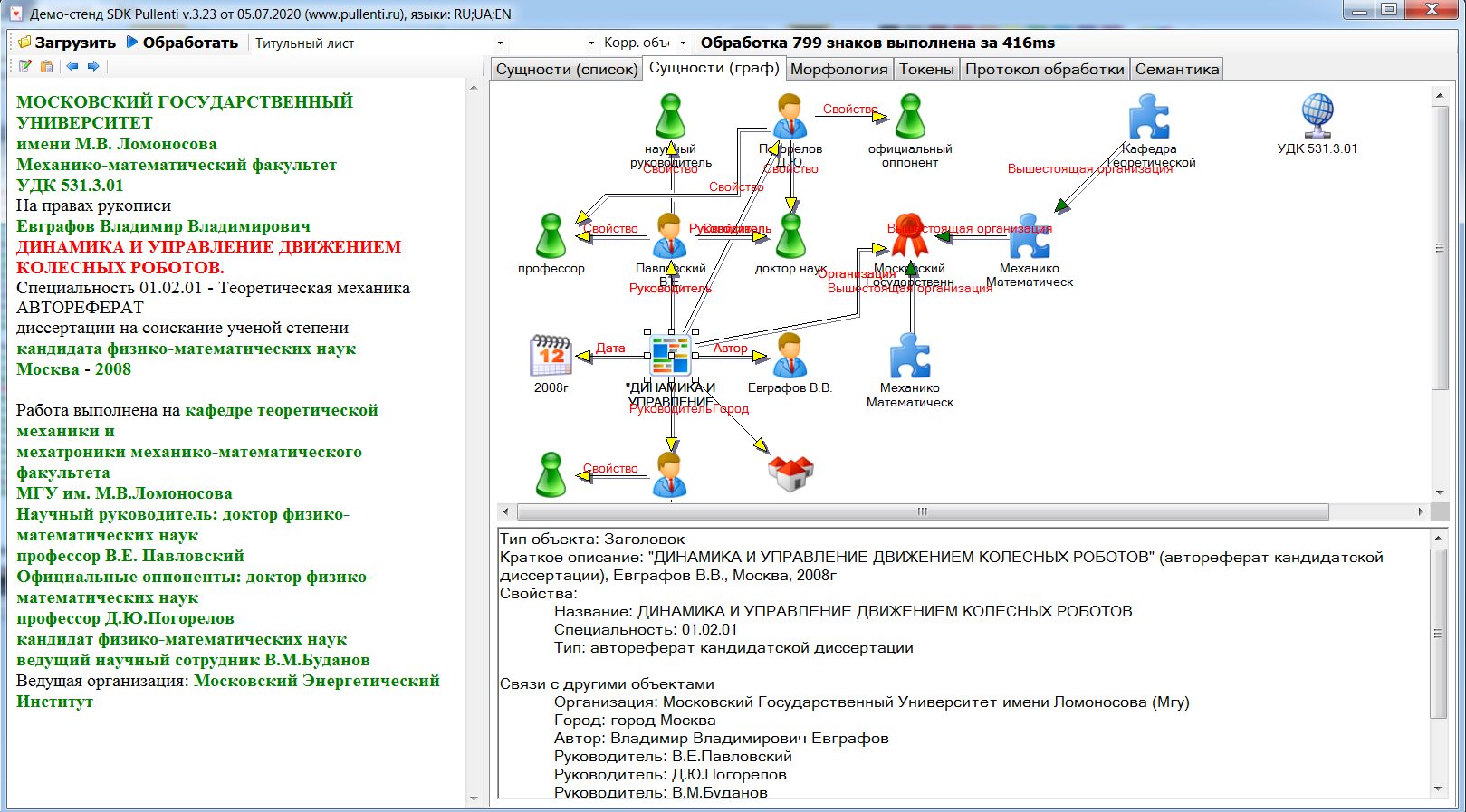
На вкладке "Объекты (граф)" те же сущности выводятся в виде графа, причём это не семантический граф, а граф между сущностями, в котором дуги соответствуют значениям атрибутов Value с типом Referent. Внизу выводятся атрибуты текущей сущности, а в тексте - её вхождения. Иконка для визуализации получается функцией GetImageId.
На вкладке "Морфология" выводится список MorphToken, возвращаемый функцией Process.
На вкладке "Токены" выводятся все токены Token в иерархическом виде (напомним про MetaToken), начиная с FirstToken.
На вкладке "Протокол обработки" выводится информация о том, какие задействовались анализаторы и сколько они работали - это список Log.
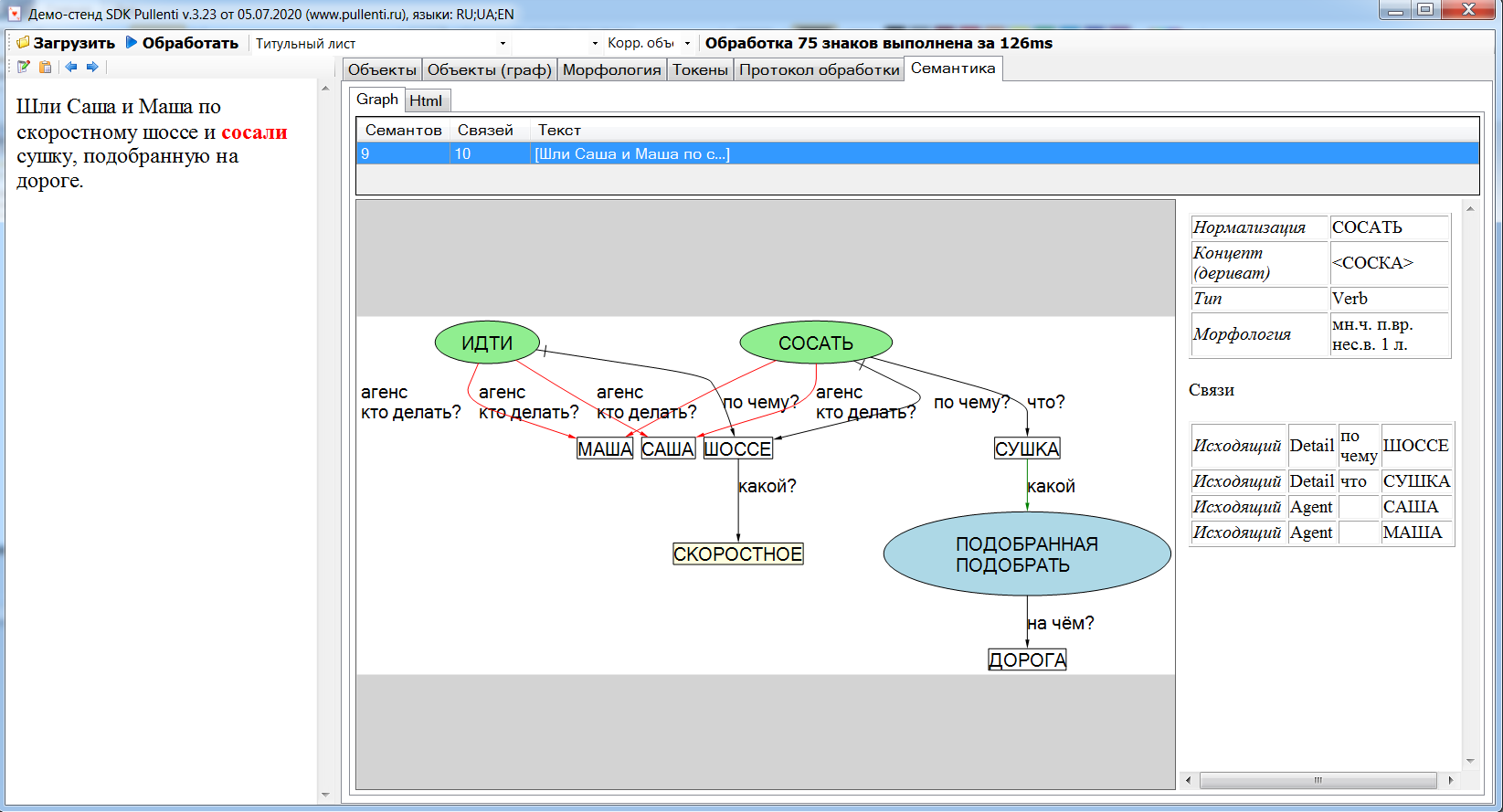
На вкладке "Семантика" отображается результат семантического анализа SemDocument.
Обработка на сервереСервер Pullenti.Server.dll реализован на .NET Core и работает на любых платформах под управление движка dotnet.
Например, из Windows он запускается как dotnet Pullenti.Server.dll.
Сервер реализует http-протокол: получает на вход POST-данные для обработки и отпраляет обратно результат.
Для чего он нужен? Для Python и Javascript он может существенно ускорить обработку по сравнению с прямым анализом через SDK: для Python примерно в 20 раз, для Javascript - в 4-5 раз. Для C# и Java скорость примерно одинакова, но может быть по каким-либо причинам нужно вынести обработку из основого потока.
По умолчанию, сервер работает через порт 1111, но можно указать и любой другой через параметр командной строки -port номер. Если сделать к нему GET-запрос без параметров (например, набрав в браузере http://localhost:1111), то сервер вернёт номер версии SDK в виде строки ASCII. Сервер останавливается, если нажать в консоли любую клавишу, или можно просто срубить процесс. Если задать ключ -noterminal, то в консоль ничего выводиться не будет, а также ожидать нажатия клавиши (это нужно для некоторых режимов использования под Linux).
Данные для сервера и парсинг результата не нужно делать самим, а использовать функции из класса ServerService. В частности, функция PreparePostData формирует массив байт для отправки, а CreateResult формирует результат AnalysisResult так, как будто выполнение происходило локально через Process. По идее, результат и должен получаться идентичным, если версия SDK совпадает с версией SDK на сервере.
Функция GetServerVersion возвращает версию SDK на сервере, а функция ProcessOnServer вызывает функцию подготовки POST-данных, делает запрос на сервере и декодирует результат. Функции PreparePostData и CreateResult намеренно сделаны, чтобы пользователь мог сам делать более эффективные запросы.
ВНИМАНИЕ! Если на обрабатываемых текстах сервер иногда "зависает", то просьба запустить его с ключом -errorpath, указав папку, куда будут записываться тексты, на которых происходит сбой или зависание. Перед обработкой текст записывается в файл со случайным именем в эту папку, после успешной обработки файл удаляется. Соответственно остающиеся файлы в этой папке содержат тексты, который присылайте разработчикам Pullenti для исправления алгоритма.